![[python] 파이썬으로 코로나 현황 출력하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FlCRYC%2Fbtq8Ie5vpYw%2FAAAAAAAAAAAAAAAAAAAAAFVLXZqdyLQUCS5Xgdhipg3qJ6a4jUhjrBJCYkM7wDXN%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3Dor%252BCiFTKVdPcf0PEWgTPLITIZE4%253D)
Life is too short, You need python
Python crawling
현재의 인터넷은 무수히 많은 정보들로 가득하다 따라서 본인이 찾으려는 정보를 찾기위해서는 크고 작은 노력들이 요구된다. 정보가 범람하는 시대에 원하는 정보를 자동으로 구해오는 프로그램을 구현하는 것은
Python에는 다양한 라이브러리가 존재한다. 크롤링을 하기위해서는 2가지의 라이브러리가 필요하다.
requsets, Beautifulsoup이다.
requesets는 html소스를 가져오고
Beautifulsoup이 Python이 이해할 수 있는 구조로 변환하는 파싱역할을 한다.
터미널에 'pip install requests', 'pip install bs4'를 입력해 다운을 받자.
import requests
from bs4 import BeautifulSoup
1. 다운을 받은 후 를 입력해줘서 다운받은 라이브러리를 참조한다.
html = requests.get("https://search.naver.com/search.naver?sm=tab_sug.top&where=nexearch&query=%EC%BD%94%EB%A1%9C%EB%82%98")
2. 네이버에서 코로나를 검색한 주소를 페이지 요청으로 html 변수에 저장한다.
sㅗoup= BeautifulSoup(html.text, 'html.parser')
3. soup라는 변수에 html.text를 파이썬에서 해석이 가능하게 파싱작업을 거친다.
data1=soup.find('div',{'class':'status_today'})
4. 우리가 필요한 부분을 개발자 모드(f12)를 통해 확인하자.
우리는 국내발생과 해외유입 수를 추출을 할 것이다.
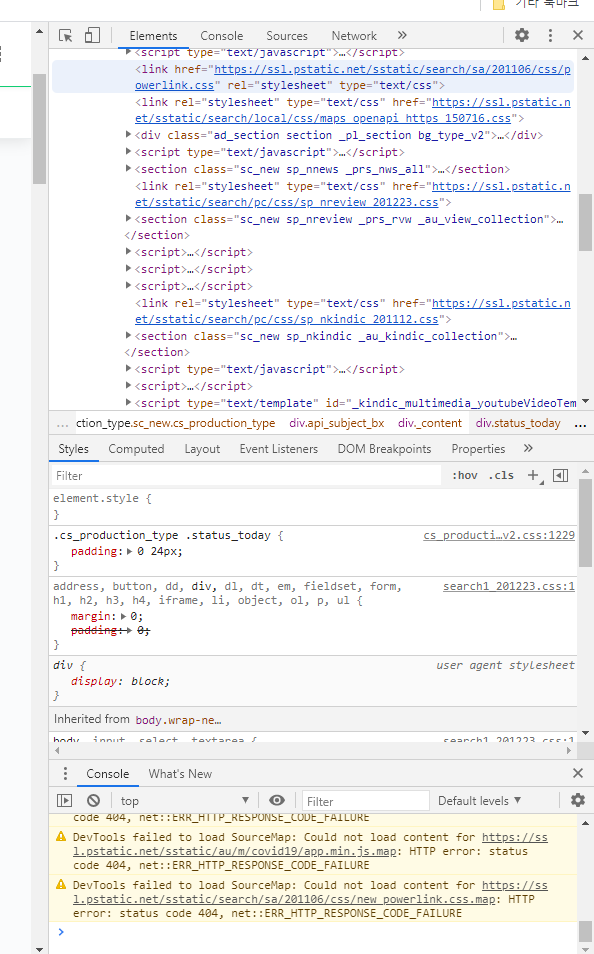
누르면 위와 같은 이미지에서 왼쪽 위를 살펴보면

이와 같은 마크를 표시해
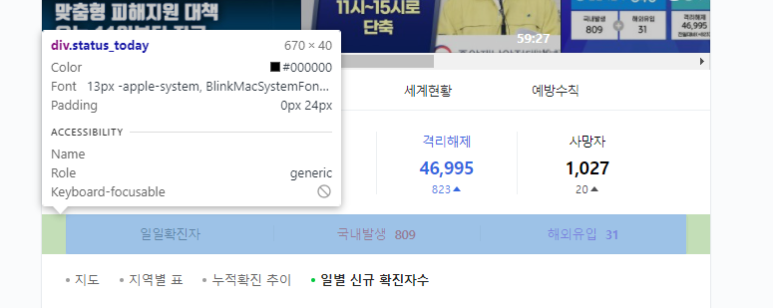
마우스를 저기 초록색에 대면 저런식으로 큰 틀을 잡는다.
크롤링은 점점 좁혀가는 것이다.
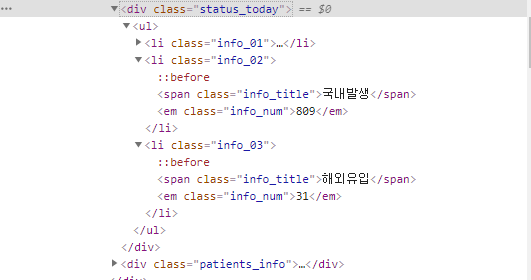
클릭하면 나온 status_today의 하위를 열어보면 추출을 원하는
국내발생 809와 해외유입 31이 있는 것을 확인했다.
data1=soup.find('div',{'class':'status_today'})
변수=변수.find('태그명',{'class':'하위클래스네임}) 이 대표적이며
soup는 위에서 html을 파싱작업을 해주었다.
data2=data1.find('ul')
data1에 있는 것 중 'ul'이라는 태그를 불러와 data2에 저장한다.
data3=data2.find('li',{'class','info_02'})
data2에 있는 것 중 'li'이라는 태그에 info_02라는 클래스를 불러와 data3에 저장한다.
data4=data2.find('li',{'class','info_03'})
data2에 있는 것 중 'li'이라는 태그에 info_03라는 클래스를 불러와 data4에 저장한다.
find_corona_kr=data3.find('em',{'class':'info_num'}).text
data3에 있는 것 중 'em'태그를 갖고 info_num이라는 문자를 불러 저장한다.
find_corona_fc=data4.find('em',{'class':'info_num'}).text
data4에 있는 것 중 'em'태그를 갖고 info_num이라는 문자를 불러 저장한다.
print("국내발생: "+find_corona_kr)
print("해외유입: "+find_corona_fc)
위와 같은 명령어를 실행하면 다음과 같다.
-2021.01.06 기준-

-완성된 코드-
import requests
from bs4 import BeautifulSoup
html = requests.get("https://search.naver.com/search.naver?sm=tab_sug.top&where=nexearch&query=%EC%BD%94%EB%A1%9C%EB%82%98")
soup= BeautifulSoup(html.text, 'html.parser')
data1=soup.find('div',{'class':'status_today'})
data2=data1.find('ul')
data3=data2.find('li',{'class','info_02'})
data4=data2.find('li',{'class','info_03'})
find_corona_kr=data3.find('em',{'class':'info_num'}).text
find_corona_fc=data4.find('em',{'class':'info_num'}).text
print("국내발생: "+find_corona_kr)
print("해외유입: "+find_corona_fc)
크롤링을 통해 코로나 현황을 불러오는 것을 포스팅 해보았습니다.
크롤링은 매우 유용하게 쓰일 수 있는 작업이라고 생각됩니다. 크롤링을 통해 날씨, 마스크, 미세먼지 등 다양한 용도로 쓰일 수 있습니다. 모두 다 하는 방법은 같고 방식이 조금 달라서 현재 포스팅된 개념으로 웹에 올라와져 있는 정보는 출력이 가능합니다.